1 Intro
The RStudio conference (cleverly named rstudio::conf) is coming up at the end of
January. This is the first time I’ll be attending, and I’m really looking forward to it!
There will be four concurrent presentations during most of the two main days of the conference (Jan 29th and 30th). Unfortunately, it’s a little challenging to visualize the schedule and pick which talk to attend using the official conference agenda page.
Mara Averick (@dataandme) tweeted about a
handy pdf she created that lays out the schedule of talks.
🎉 Stoked the #rstudioconf schedule is out!
— Mara Averick (@dataandme) November 26, 2019
🗓 "Agenda - rstudio::conf San Francisco" https://t.co/4bIQgEpsmM
Very unofficial version in a format I like looking at: https://t.co/SaTcFojUTe pic.twitter.com/KbKqU61Maz
I came across her tweet one 🐇 🕳 too late, however 🤦. Prior to that discovery I had decided it would be “fun” to inspect the conference agenda page, see what it would take to scrape the details for all the presentations, and try to display them in a nicer format. Yada, yada, yada, here’s a blog post for ya.
Before this thing is over, you’ll (hopefully) learn how
use R to create an interactive schedule of the conference talks that looks like this:

2 Setup
2.1 Packages
Let’s start by loading some packages. I like to use the pacman package from
Tyler Rinker (@tylerrinker) to handle things. The p_load function takes
a vector of package names, installs them if necessary, and then loads them.
pkgs <- c("ggplot2", "ggsci", "jsonlite", "magick", "magrittr", "rmarkdown",
"robotstxt", "scales", "splashr", "timevis", "urltools", "data.table")
pacman::p_load(char=pkgs)2.2 Page rendering tool
We’ll use the splashr package from Bob Rudis
(@hrbrmstr) to load the page and grab the content we need, all from the comfort of R.
Why do we need this? As usual the great R community 🙌 has developed many
packages for web-related tasks. The
rvest package is one that can be very useful in certain situations. But many
times our old pal Javascript is invited to the party and
adds some complications that require a
tool like Splash that can render it. The splashr package looks well
supported and it’s relatively new so I wanted to give it a spin.
You can read through the splashr intro vignette,
but it’s pretty straightforward to get started. Just install docker if you haven’t
already and then run install_splash() in R.
Now let’s fire up a Splash docker container, which will be the thing that does the thing (i.e. scrape the page).
spCon <- start_splash()## Detected API version '1.40' is above max version '1.39'; downgrading## Error pulling image from DockerHub.
I didn’t have problems running this initially, but for whatever reason when I went to make this post it started
complaining a little about the (docker?) API version. Hopefully it works for those of you following along at home! You
can check the status with the following function.
splash_active()## Status of splash instance on [http://localhost:8050]: ok. Max RSS: 1,026 Mb## [1] TRUE2.3 Check robots.txt
Now that we’ve made a splash 🙄, let’s specify the URL of the conference agenda page that we’ll be
scraping and check the page’s robots.txt. Use the handy
and aptly named robotstxt package from Peter Meissner
(@peterlovesdata) to make sure it’s ok to scrape the event page.
## Page to scrape
urlConf <-
"https://web.cvent.com/event/36ebe042-0113-44f1-8e36-b9bc5d0733bf/websitePage:34f3c2eb-9def-44a7-b324-f2d226e25011"
## Parse the domain
urlDomain <- urltools::domain(urlConf)
## Get the robots.txt file
rt <- get_robotstxt(urlDomain)
## Check robots.txt
pa <- paths_allowed(domain=urlDomain)
rt## # robots.txt for https://web.cvent.com
## # : robots.txt,v 1.00 2017/11/28
## User-agent: Wget
## Disallow:/
## User-agent: Wget/1.9
## Disallow:/
## User-agent: Wget/1.6
## Disallow:/
## User-agent: Wget/1.5.3
## Disallow:/
## User-agent: AhrefsBot
## Disallow: /
## Sitemap: https://web.cvent.com/sitemap?environment=P2pa## [1] TRUEThe output of paths_allowed is TRUE, so we’ve got the “all clear” to scrape this thing. Responsibly, of course.
3 Scrape
3.1 Load the page
We can fetch the page and all its accouterments using the splashr::render_json function. I initially set a wait
value of 3 seconds, which apparently was not enough time for the page to load on my machine; YMMV. If you want to see
an image of the rendered page (hopefully after it’s fully loaded), you can set the PNG argument to TRUE and then
display it with magick::image_read.
## Load the page and take a screenshot
pg <- render_json(url=urlConf, wait=5, png=TRUE, response_body=TRUE)
#pg$html
## Show the screenshot
#render_png(url=urlConf, wait=3) ## Alt method, if you just want the screenshot and nothing else
pgPNG <- image_read(base64_dec(pg$png))
pgPNG
3.2 Examine the content
We’ve got everything set up, so now we need to become familiar with the structure and content of the page we’re scraping. (IRL, you’d want to start by investigating the page and then determine which tools to use to scrape it, but as your cheesy cooking show host I’ve already pre-baked that part for this blog post.) Load the conference agenda page in your desktop browser, open the web development tools, and go to the network tab. (The keyboard shortcut to the network tab in Firefox is ⌘+⌥+E on macOS and Ctrl+Shift+E in Windows/Linux.) You’ll likely want to clear the existing results and reload the page.
We could try to scrape the rendered HTML, but it seems that the content for each session is only revealed after clicking on the session. We could probably do that with Splash, but there is an easier option. I had a hunch that the conference session details would be stored in a JSON file, and that turned out to be correct. Filter (by selecting XHR) or sort the network results by type and look for a JSON file with “products” in the name. Check the response tab, which contains the formatted contents of the file.



3.3 Get the JSON
If you’re just tuning in, we know the JSON with the conference session details is out there 👽. Our
friend splashr saved an HTTP archive (HAR) for us
earlier, so we can grab it from that. But first we need to find it. Take a look at the HAR object.
## Get the HTTP ARchive (HAR) file that contains a list of page resources
## Alt method if you just want the HAR and nothing else:
#har <- render_har(url=url, wait=3, response_body=TRUE)
har <- pg$har
har## --------HAR VERSION--------
## HAR specification version: 1.2
## --------HAR CREATOR--------
## Created by: Splash
## version: 3.4
## --------HAR BROWSER--------
## Browser: QWebKit
## version: 602.1
## --------HAR PAGES--------
## Page id: 1 , Page title: Agenda - rstudio::conf San Francisco
## Page id: 2 , Page title:
## --------HAR ENTRIES--------
## Number of entries: 293
## REQUESTS:
## Page: 1
## Number of entries: 38
## - https://www.cvent-assets.com/event-guestside-site/assets/css/styles.prod....
## - https://www.cvent-assets.com/event-guestside-site/assets/runtime.prod._v5...
## - https://www.cvent-assets.com/event-guestside-site/assets/vendor.prod._v5....
## - https://www.cvent-assets.com/event-guestside-site/assets/styles.prod._v5....
## - https://www.cvent-assets.com/event-guestside-site/assets/main.prod._v5.a7...
## ........
## - https://www.cvent-assets.com/event-guestside-site/assets/fonts/Lato-Bold_...
## - https://www.cvent-assets.com/event-guestside-site/assets/fonts/lato-v13-l...
## - https://www.cvent-assets.com/event-guestside-site/assets/fonts/Lato-Black...
## - https://www.cvent-assets.com/event-guestside-site/assets/fonts/Lato-Black...
## - https://web.cvent.com/event_guest/v1/websiteContent/36ebe042-0113-44f1-8e...
## Page: 2
## Number of entries: 255
## - https://web.cvent.com/event/36ebe042-0113-44f1-8e36-b9bc5d0733bf/websiteP...
## - https://www.cvent-assets.com/event-guestside-site/assets/1.prod._v5.754ca...
## - https://www.cvent-assets.com/event-guestside-site/assets/12.prod._v5.672e...
## - https://www.cvent-assets.com/event-guestside-site/assets/16.prod._v5.9d01...
## - https://www.cvent-assets.com/event-guestside-site/assets/92.prod._v5.3948...
## ........
## - https://custom.cvent.com/127B71FE97E440DFB772841518587A73/files/event/36e...
## - https://custom.cvent.com/127B71FE97E440DFB772841518587A73/files/event/36e...
## - https://custom.cvent.com/127B71FE97E440DFB772841518587A73/files/event/36e...
## - https://custom.cvent.com/127B71FE97E440DFB772841518587A73/files/event/36e...
## - https://custom.cvent.com/127B71FE97E440DFB772841518587A73/files/event/36e...
Gowrgeous, isn’t it? Before I start to get emotional or even a little
verklempt, let’s let the computers tawlk amongst
themselves and find the JSON file fowr us.

3.3.1 Session
The chunk of R code below loops lapplys through all the entries in the HAR log (har$log$entries), looks for JSON
files (x$response$content$mimeType %like% "json") that contain “products” in the name
(x$response$url %like% "products"), and returns the indices for those matching files (which).
## Determine the index for the JSON file containing the conference session details
sessionIdx <-
lapply(har$log$entries, function(x)
x$response$content$mimeType %like% "json" & x$response$url %like% "products"
) %>%
unlist %>%
which
sessionIdx## [1] 45
Now we can get the text from the response for item 45 (the products JSON file) from the HAR. Let’s also use
the awesome data.table package created by Matt Dowle
(@mattdowle) to reformat the JSON into a table. There are a few naughty nested
JSON elements that don’t add much value (fees and associatedRegistrationTypes) that I’m removing here.
## Get the JSON
sessionJSON <-
har_entries(har)[[sessionIdx[1]]] %>%
get_response_body("text")
## Convert from JSON to data.table
session <-
fromJSON(sessionJSON)$sessionProducts %>%
lapply(function(x) {
#as.data.table(x[!lapply(x, length) > 1L]) ## Drop any columns with more than one row per session
as.data.table(x[!names(x) %chin% c("fees", "associatedRegistrationTypes")]) ## Drop specific columns
}) %>%
rbindlist(fill=TRUE)Let’s look at the structure of the resulting table.
## Print the table; takes up too much space for this blog
#rmarkdown::paged_table(session)
## Examine the structure of a row in the table
exampleId <- "d8d901d9-bdb6-4392-83a9-3ad5addbbf53"
str(session[id==exampleId])## Classes 'data.table' and 'data.frame': 2 obs. of 23 variables:
## $ categoryId : chr "c32f17f6-2464-476b-859b-d8ab4d26556b" "c32f17f6-2464-476b-859b-d8ab4d26556b"
## $ waitlistCapacityId : chr "d8d901d9-bdb6-4392-83a9-3ad5addbbf53_waitlist" "d8d901d9-bdb6-4392-83a9-3ad5addbbf53_waitlist"
## $ startTime : chr "2020-01-29T18:00:00.000Z" "2020-01-29T18:00:00.000Z"
## $ endTime : chr "2020-01-29T19:00:00.000Z" "2020-01-29T19:00:00.000Z"
## $ isOpenForRegistration : logi TRUE TRUE
## $ isIncludedSession : logi FALSE FALSE
## $ isWaitlistEnabled : logi FALSE FALSE
## $ sessionCustomFieldValues:List of 2
## ..$ : NULL
## ..$ : NULL
## $ richTextDescription : chr "{\"format\":\"draftjs-nucleus\",\"version\":1,\"content\":{\"blocks\":[{\"key\":\"bges0\",\"text\":\"Recent pro"| __truncated__ "{\"format\":\"draftjs-nucleus\",\"version\":1,\"content\":{\"blocks\":[{\"key\":\"bges0\",\"text\":\"Recent pro"| __truncated__
## $ displayPriority : int 0 0
## $ showOnAgenda : logi TRUE TRUE
## $ speakerIds :List of 2
## ..$ :List of 3
## .. ..$ speakerId : chr "310ea87b-1917-4252-a3f0-10c737b5a73a"
## .. ..$ speakerCategoryId: chr "86502b84-9704-4416-baf2-ec9edc15fd4f"
## .. ..$ sessionId : chr "d8d901d9-bdb6-4392-83a9-3ad5addbbf53"
## ..$ :List of 3
## .. ..$ speakerId : chr "3cb4488b-81dd-4ad3-b94a-90987821825c"
## .. ..$ speakerCategoryId: chr "86502b84-9704-4416-baf2-ec9edc15fd4f"
## .. ..$ sessionId : chr "d8d901d9-bdb6-4392-83a9-3ad5addbbf53"
## $ code : chr "" ""
## $ description : chr "<div class=\"ag87-crtemvc-hsbk\"><div class=css-zuif4x><p class=\"carina-rte-public-DraftStyleDefault-block\"><"| __truncated__ "<div class=\"ag87-crtemvc-hsbk\"><div class=css-zuif4x><p class=\"carina-rte-public-DraftStyleDefault-block\"><"| __truncated__
## $ id : chr "d8d901d9-bdb6-4392-83a9-3ad5addbbf53" "d8d901d9-bdb6-4392-83a9-3ad5addbbf53"
## $ capacityId : chr "d8d901d9-bdb6-4392-83a9-3ad5addbbf53" "d8d901d9-bdb6-4392-83a9-3ad5addbbf53"
## $ name : chr "Data, visualization, and designing with AI" "Data, visualization, and designing with AI"
## $ status : int 2 2
## $ type : chr "Session" "Session"
## $ defaultFeeId : chr "00000000-0000-0000-0000-000000000000" "00000000-0000-0000-0000-000000000000"
## $ closedReasonType : chr "NotClosed" "NotClosed"
## $ locationName : chr "Room 2" "Room 2"
## $ locationCode : chr "Room 21578074754834" "Room 21578074754834"
## - attr(*, ".internal.selfref")=<externalptr>Still a bit of an eyesore, but it’s in a tabluar and mostly-tidy format, so we can work with it.
3.3.2 Speaker
The speaker name, bio, and other info is stored in a separate JSON file. The code below finds and retrieves the file in a similar fashion as the session info.
speakerIdx <-
lapply(har$log$entries, function(x)
x$response$content$mimeType %like% "json" & x$response$url %like% "Sessions"
) %>%
unlist %>%
which
## Get the JSON
speakerJSON <-
har_entries(har)[[speakerIdx[1]]] %>%
get_response_body("text")
## Convert from JSON to data.table
speaker <-
fromJSON(speakerJSON)$speakerInfoSnapshot$speaker %>%
lapply(as.data.table) %>%
rbindlist(fill=TRUE)
## Print the table; takes up too much space for this blog
#rmarkdown::paged_table(speaker)
## Examine the structure of a row in the table
str(speaker[1])## Classes 'data.table' and 'data.frame': 1 obs. of 17 variables:
## $ id : chr "78ff1c9c-02da-461b-a661-155b4ec3d15a"
## $ categoryId : chr "86502b84-9704-4416-baf2-ec9edc15fd4f"
## $ firstName : chr "Ian"
## $ lastName : chr "Lyttle"
## $ prefix : chr ""
## $ company : chr "Schneider Electric"
## $ title : chr ""
## $ biography : chr "Ian Lyttle works at Schneider Electric as a data scientist, with a focus on visualization. He is an enthusiasti"| __truncated__
## $ designation : chr ""
## $ displayOnWebsite : logi TRUE
## $ facebookUrl : chr ""
## $ twitterUrl : chr "https://twitter.com/ijlyttle"
## $ linkedInUrl : chr "https://www.linkedin.com/in/ian-lyttle-a4a02917/"
## $ order : int 81
## $ profileImageFileName: chr "lyttle2017lores1567810718091.png"
## $ profileImageUri : chr "https://custom.cvent.com/127B71FE97E440DFB772841518587A73/files/event/36ebe042011344f18e36b9bc5d0733bf/lyttle20"| __truncated__
## $ websites :List of 1
## ..$ : NULL
## - attr(*, ".internal.selfref")=<externalptr>3.3.3 Category
We need one final JSON file containing the category info for the sessions.
categoryIdx <-
lapply(har$log$entries, function(x)
x$response$content$mimeType %like% "json" & x$response$url %like% "account"
) %>%
unlist %>%
which
## Get the JSON
categoryJSON <-
har_entries(har)[[categoryIdx[1]]] %>%
get_response_body("text")
## Convert from JSON to data.table
category <-
fromJSON(categoryJSON)$sessionCategories %>%
lapply(as.data.table) %>%
rbindlist(fill=TRUE)
## Print the table; takes up too much space for this blog
#rmarkdown::paged_table(category)
## Examine the structure of a row in the table
str(category[3])## Classes 'data.table' and 'data.frame': 1 obs. of 3 variables:
## $ id : chr "9541ec43-0d38-4c2a-a1d3-765a3e1d1e01"
## $ name : chr "Learning and Using R"
## $ description: chr ""
## - attr(*, ".internal.selfref")=<externalptr>4 Prepare
Ok, that was a decent amount of work, but surely now we’re ready to do something more exciting, right? Right? 🦗
In Data Science, 80% of time spent prepare data, 20% of time spent complain about need for prepare data.
— Big Data Borat (@BigDataBorat) February 27, 2013
4.1 Convert dates/times
We want to know the dates and times of the rstudio::conf sessions, but they’re currently stored as text in the tables we’ve scraped. Since the event is in San Fran, we also want to display the time using the US/Pacific time zone rather than UTC. There are multiple date/time columns, so we can loop through them and apply the same transformation to each.
The code below converts all columns with “time” in the name. I use data.table all the time, but it took a few
trips to Google and re-finding this Stackoverflow answer before I
eventually remembered the syntax for applying a function to each column in a table. Also, we could probably use
lubridate to make the date/time conversion a little easier, but I’m feeling
complicated.

## Function to convert a string to POSIXct and change the timezone format
dateTimeConvert <- function(x, fmt, tzOrig, tzNew) {
.POSIXct(as.integer(as.POSIXct(x, format=fmt, tz=tzOrig)), tz=tzNew)
}
cols <- names(session)[names(session) %like% "[Tt]ime"]
cols## [1] "startTime" "endTime"## Convert timestamps from UTC to Pacific
for(n in cols)
set(session, j=n, value=dateTimeConvert(session[[n]], "%FT%T", "UTC", "US/Pacific"))
## Examine the structure of the date/time columns
str(session[, mget(cols)])## Classes 'data.table' and 'data.frame': 137 obs. of 2 variables:
## $ startTime: POSIXct, format: "2020-01-27 09:00:00" "2020-01-27 09:00:00" ...
## $ endTime : POSIXct, format: "2020-01-28 17:00:00" "2020-01-28 17:00:00" ...
## - attr(*, ".internal.selfref")=<externalptr>4.2 Add category name and style
A few steps ago, we grabbed a JSON file containing the session categories. In a few steps from now, we’ll color code each session/talk based on the category. Here is an example:
Let’s prep for that by creating a color palette and assigning a color to each session. The
ggsci package from Nan Xiao (@nanxstats) et
al. has some nice color palettes. The Springfield collection from the Simpsons™ palette has a max of 16 colors,
but it turns out there are 34 categories in the rstudio::conf data.

Not to worry, we can use grDevices::colorRampPalette to interpolate as many colors as we need.
nColorsMax <- 16
## How many colors do we need?
nColors <- nrow(category)
## Create the palette
styleColors <- colorRampPalette(ggsci::pal_simpsons("springfield")(min(c(nColors, nColorsMax))))(nColors)
## Examine what we've got
scales::show_col(styleColors)
That’ll do. Now we need to create a little CSS to style the
colors for the border, background, and text of the session info boxes. For the border we can use the colors from the
palette we created. To differentiate it from the border color, let’s set the transparency of the background color to
70%. One quick hack–that may not work in all browsers–is to add the
transparency (alpha) value at the end of the normal hex color value. For example,
#360335 would become
#360335B3.
(B3 is the hex representation for 70%.) For the text let’s go with white, since most of the palette colors are on the
darker side.
The code below adds a style column to the category table that specifies the CSS to use for each category. Then it adds
the category name and style columns from the category info table to the session table, joining on the id columns. (Here
and elsewhere throughout the post I am using the data.table package to wrangle data. Check the
intro vignette if you’re
unfamiliar with the syntax.)
alpha <- 0.7
alphaHex <-
median(c(alpha, 0, 1)) * 256 %>% ## Make sure alpha is between 0 and 1, and multiply by 256
as.integer %>% ## Convert to a whole number
as.hexmode ## Convert to hexadecimal
## Add the CSS style column
category[, style:=sprintf(
"color: white; background-color: %1$s%2$s; border-color: %1$s;", styleColors, alphaHex)]
## Add the category name and style to the session table
session[category, `:=`(categoryName=i.name, style=style), on=c(categoryId="id")]4.3 Split out list columns
Our JSON files had some nesting that we’ve so far ignored. Let’s rectify that by splitting out those list columns (which currently have multiple rows per row in the main table) into their own tables.
## This table links the session to the speaker(s)
sessionSpeakerId <-
session[, .(rbindlist(speakerIds))] %>%
unique ## Remove duplicate rows
## Print a few rows
#rmarkdown::paged_table(sessionSpeakerId[1:5])
## Examine the structure
#str(sessionSpeakerId)
## Column names
names(sessionSpeakerId)## [1] "speakerId" "speakerCategoryId" "sessionId"## This table contains links to social media and other types of pages for the speakers
speakerLink <-
speaker[, .(rbindlist(websites))] %>%
unique ## Remove duplicate rows
## Print a few rows
#rmarkdown::paged_table(speakerLink[1:5])
## Examine the structure
#str(speakerLink)
## Column names
names(speakerLink)## [1] "id" "relatedUrl" "isDisplay"
## [4] "relatedUrlName" "relatedUrlCategoryId" "speakerId"4.4 Speaker info for each session
We will eventually create a bunch of boxes containing the session name, but to be more informative we’ll want to add popup messages that provide more details for each session, including info about the speaker. The code below contains a function that combines the company and title for each speaker, handling cases where one or the other or both are missing.
## Format the speaker's combined title and company
titleCompany <- function(company, title) {
## Replace semicolon with slash in title, since we'll use semicolon to delimit multiple speakers later
title <- gsub("; ", " / ", title)
## Convert NA to empty string
if(is.na(title)) title <- ""
if(is.na(company)) company <- ""
## Check for empty string
valT <- title==""
valC <- company==""
## If both are empty, return empty
if(all(c(valT, valC))) return("")
## Combine the company and title
val <-
if(any(c(valT, valC))) paste0(title, company) else
paste(c(title, company), collapse=", ")
## Wrap in parenthesis
return(sprintf("(%s)", val))
}The sessionSpeakerId table that we split out in the previously lets us relate the speaker
to the session. Let’s use it now to merge those two tables. While we’re at it, we’ll use that speaker title/company
function to format the speaker info. If there are multiple speakers per session, we’ll collapse it into a single text
value separated by a semicolon.
## Add the session and category identifiers to the speaker table
## The result contains one row per combination of session and speaker
sessionSpeaker <- merge(sessionSpeakerId, speaker, by.x="speakerId", by.y="id")
sessionSpeakerInfo <-
## Select the columns we need
sessionSpeaker[, .(sessionId, speakerId, firstName, lastName, title, company)] %>%
## Remove duplicates
unique %>%
## Format the speaker info
.[, speakerInfo:=trimws(paste(firstName, lastName, titleCompany(title, company))), by=.(sessionId, speakerId)] %>%
## Collapse multiple speakers into a single semicolon-delimited value
.[, .(speakerInfo=paste(unique(speakerInfo), collapse="; ")), by=.(sessionId)]
sessionSpeakerInfo[, .(speakerInfo)]## speakerInfo
## 1: Andrew Mangano (Salesforce, Data Intelligence Lead)
## 2: Yim Register (RStudio/University of Washington)
## 3: Jared Lander (Lander Analytics, Chief Data Scientist)
## 4: Jonathan McPherson (RStudio, Software Engineer)
## 5: Maria Ortiz Mancera (CONABIO, Advisor)
## ---
## 119: Dani Chu (NHL Seattle, Quantitative Analyst - Statistics)
## 120: Tyson Barrett (Utah State University, Research Assistant Professor)
## 121: David Smith (Microsoft, Cloud Advocate)
## 122: BenJoaquin Gouverneur (Plenty Unlimited, Inc., Manager, Datalab)
## 123: Travis Gerke (Moffitt Cancer Center, Scientific Director of Collaborative Data Services)Now we can add the speaker info to the session table.
session[sessionSpeakerInfo, speakerInfo:=speakerInfo, on=c(id="sessionId")]
names(session)## [1] "categoryId" "waitlistCapacityId"
## [3] "startTime" "endTime"
## [5] "isOpenForRegistration" "isIncludedSession"
## [7] "isWaitlistEnabled" "sessionCustomFieldValues"
## [9] "richTextDescription" "displayPriority"
## [11] "showOnAgenda" "speakerIds"
## [13] "code" "description"
## [15] "id" "capacityId"
## [17] "name" "status"
## [19] "type" "defaultFeeId"
## [21] "closedReasonType" "locationName"
## [23] "locationCode" "categoryName"
## [25] "style" "speakerInfo"4.5 Identify workshops vs talks
Conference attenders can sign up for two-day workshops on Jan 27th and 28th. For the purposes of this post though, we only care about the talks on the 29th and 30th. (Remember the intro, from like 30 minutes ago? We’re trying to make a friendlier display of the schedules so we can choose which of the four concurrent sessions to attend.)
How can we classify the session info into “workshop” vs “talk”, using only the text descriptions?! This is a job for
BERT-Large! Or–if you fancy the uncased case–bert-large.
Sorry for the anti-climax, but it turns out that the workshops don’t have room location information while the talks do; no need for any fancy NLP here. Also, we could have just filtered by date 😉. But seriously, someone needs to create a state-of-the-art-for-this-nanosecond transformer called SUPER-GROVER™.

Using that breakthrough insight, let’s subset the session info to only those rows that have location data. The code below also grabs the global session identifier, start and end times, class name and description, location, and speaker info. We’ll use these columns for our final output. We’ll also do one last check for duplicate rows.
## Subset the talks, select the relevant columns, and de-duplicate
talks <-
session[!is.na(locationName), .(
id, startTime, endTime, categoryName, name, description, locationName, speakerInfo, style)] %>%
unique
## Make sure there aren't any dupes left
talksCheckDupes <- talks[, .N, by=id][N>1]
if(nrow(talksCheckDupes) > 0) warning("There are multiple rows with the same identifier!")4.6 Format talk titles
Judging from the length of the talk titles (and this blog post), the R community can be pretty wordy at times! Congrats to “The good, the bad and the ugly: What I learned while consulting across the business as a data scient” for being the longest title. It looks like they actually ✂ off titles at 100 characters.
ggplot(talks[, .(nameLength=nchar(name))], aes(x=nameLength)) +
geom_histogram(binwidth=2) +
labs(x="Number of characters in session title", y="Count") +
theme_minimal(base_size=18)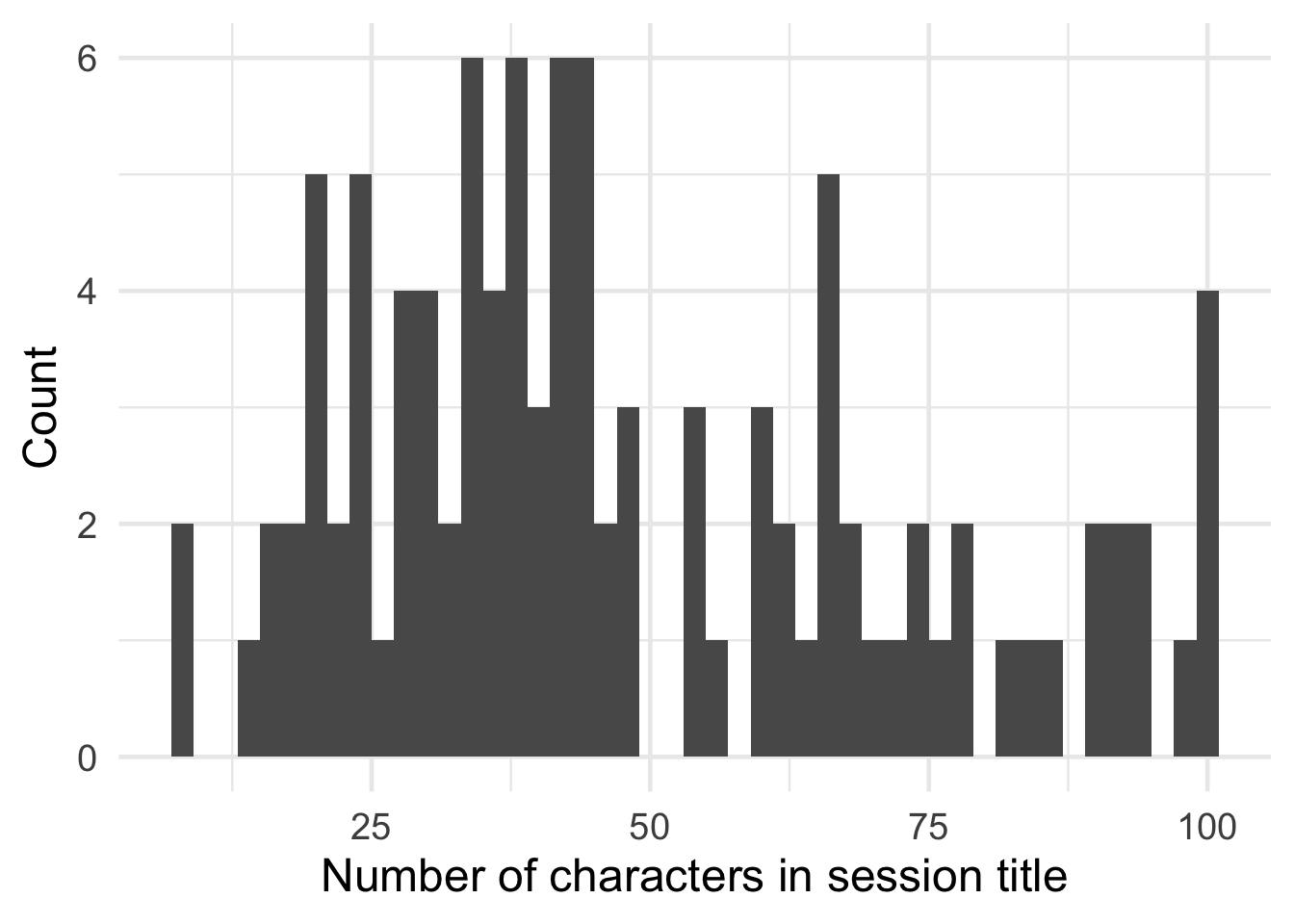
While informative, the long titles are a challenge to display compactly. For the schedule visualization tool we’d like
to reshape the text a bit, breaking long titles into multiple rows. We can use strwrap to split the text at word
boundaries, inserting a line break after 20 characters (a value chosen after trial and error).
maxWidth <- 20
#talks[, nameWrap:=substr(paste(strwrap(name, width=maxWidth), collapse="\n"), 0, maxWidth*3)]
## Break it
talks[, nameWrap:=
name %>% ## Original session name
strwrap(width=maxWidth) %>% ## Wrap it
.[1:4] %>% ## Allow up to 4 rows
na.omit %>% ## Remove blank rows if there are fewer than 4
paste(collapse="\n"), ## Collapse multiple lines into one, separated by a line break
by=name]Let’s check to make sure it worked.
## Check it
talksCheck <- talks[, .(name, nameWrap, nameLength=nchar(name))][order(-nameLength)]
## Compare the unwrapped and wrapped versions
unwrapped <- talksCheck[1, cat(name)]## The good, the bad and the ugly: What I learned while consulting across the business as a data scientwrapped <- talksCheck[1, cat(nameWrap)]## The good, the bad
## and the ugly: What
## I learned while
## consulting across4.7 Find overlapping times
Since we’re dealing with data here 🤪, it could be interesting to check for cases where multiple sessions
are scheduled at the same time and location. Using the data.table::foverlaps function, we can easily and quickly join
the table of talks to itself on the room location and start/end times and look for overlaps. First we set the key
columns that will be used in the join, making sure that the start and end times are the last two keys specified (as
required by foverlaps). Then we subset the results to remove cases where the session names being compared are
identical, since we don’t want to compare a talk to itself. In other words, we already know that Talk A is happening at
the same time and place as Talk A.
## Select relevant columns
allTalks <- talks[, .(locationName, startTime, endTime, name, speakerInfo)]
## Set the keys for the table
setkey(allTalks, locationName, startTime, endTime)
## Find the overlapping times
overlaps <- foverlaps(allTalks, allTalks, type="within")[name!=i.name][order(locationName, startTime, name)]
## Clean up the names
#setnames(overlaps, gsub("i\\.", "overlapping\\.", names(overlaps)))
overlaps[, mget(names(overlaps)[!names(overlaps) %like% "i\\."])]## locationName startTime endTime
## 1: Room 2 2020-01-30 11:16:00 2020-01-30 11:38:00
## 2: Room 2 2020-01-30 11:16:00 2020-01-30 11:38:00
## name
## 1: Designing Effective Visualizations
## 2: How Rmarkdown changed my life
## speakerInfo
## 1: Miriah Meyer (University of Utah, Professor)
## 2: Rob Hyndman (Monash University, Professor of Statistics)Uh oh. It might get a little awkward when the Effective Visualization crowd shows up to the RMarkdown party in Room 2 on Thursday at 11:16.

5 Visualize
5.1 Take 1
Now we’re finally ready to do something useful-ish! 🤨 Let’s use the geom_rect function from the
ggplot2 package to plot each talk session as a rectangle. On the x-axis the box
will stretch from the start time to the end time. Room locations will be represented by different y-axis positions.
The name of the talk will be labeled with geom_text. Flip the switch and let’s see what we’ve got!

p1 <-
ggplot(talks, aes(
ymin=as.ITime(startTime), ymax=as.ITime(endTime),
xmin=as.numeric(factor(locationName))-0.45, xmax=as.numeric(factor(locationName))+0.45)) +
geom_rect(fill="white", color="black") +
geom_text(aes(
y=as.ITime(startTime + (endTime-startTime)/2), x=as.numeric(factor(locationName)),
label=substr(name, 0, 30)), angle=0) +
scale_y_continuous(trans="reverse") +
facet_wrap(~as.IDate(startTime), ncol=1)
p1

Ok, so it might need some “finessing”. I promise it looked better full screen on a 4K monitor 🤞. But only a little.
5.2 Take 2
Let’s see if we can do better…

ggplot2 has amazing superpowers for most data visualization tasks, and we could try to tweak our first take to make it
more readable. But it’s probably better in this case to switch to another tool that is more interactive and
“web native”. I investigated using ggiraph and
Plotly; while they are both nice packages and good at what they do, they weren’t quite suited
for this task.
After more searching, I came across the timevis package. According to the
package creator Dean Attali (@daattali), it is “based on the
vis.js Timeline module and the htmlwidgets R package.” (Dean also
created beautiful-jekyll, the basis for
the Hugo template I’m using for this blog. Thanks Dean!) Let’s give it a
try!
We’ll still use the talks table, but timevis requires a second table with grouping information. In our case, the
groups are the room locations. So before plotting anything, let’s get the room info in a separate table.
rooms <-
talks[, .(id=locationName, content=locationName, order=as.numeric(factor(locationName)))][
order(order)] %>%
unique
#rooms[, style:=sprintf(
# "color: %s; background-color: %s;",
# ggsci::pal_simpsons("springfield")(nrow(rooms)),
# ggsci::pal_simpsons("springfield", alpha=0.3)(nrow(rooms)))]Finally, we’re ready to create the visualization for the talk schedule. I won’t explain every bit of the code to create
the output, since the timevis documentation and examples are pretty good. I
did spend a fair amount of time poring over the vis.js docs, especially the
configuration options and
examples, trying to determine
how to translate the Javascript instructions into R.
hoverTemplate <-
"Category: %s
Title: %s
Time: %s to %s
Speaker(s): %s
%s"
tv <-
timevis(
talks[, .(
id,
start=startTime,
end=endTime,
title=sprintf(hoverTemplate,
categoryName, ## Category
name, ## Title
format(startTime, "%I:%M%p"), format(endTime, "%I:%M%p"), ## Time
speakerInfo, ## Speaker
gsub("<.*?>", "", (description)) ## Description
),
content=gsub("\\n", "<br>", nameWrap),
group=locationName,
type="range",
style)],
groups=rooms,
options=list(
stack=FALSE, stackSubgroups=FALSE, horizontalScroll=TRUE, zoomKey="ctrlKey", width="100%",
format=list(minorLabels=list(minute="LT", hour="LT")),
end="2020-01-29 11:00:00", hiddenDates=list(start="2020-01-29 18:00:00", end="2020-01-30 08:00:00")
)
)6 Final result
ℹ
- Hover over a session to get more info about the session and the speaker.
- Click and hold your mouse inside the schedule window, and them move your mouse left or right to scroll through additional dates/times.
- Press the +/- buttons to zoom in or out on the schedule.
We could make this fancier by adding buttons to jump to specific time ranges, a dropdown to select the times for a specific session, etc. But… let’s just take the win, go home, and eat some spaghetti with syrup to celebrate!
